11.6.1.3.1 : Parallélisme sur GPU et sur FPGA
Le principe de combiner le parallélisme avec le pipeline de l'exécution des instructions et expliqué dans un article technique disponible sur le site Intel [156]OpenCL on FPGAs for GPU programmers, Acceleware, WP-2014060-1.0. Les unités graphiques de calcul (GPU) sont bien connues et depuis longtemps utilisées pour faire des calculs (General Purpose Graphic Processing Units, GPGPU). Initialement dédiées aux calculs nécessaires pour l'affichage graphique à l'écran, leur architecture est orientée vers l'application de la même opération (une transformation géométrique, par exemple) à la fois sur plusieurs valeurs (coordonnées des points en espace 3D ou 2D). Ceci est connu sous le concept de Single Instruction Multiple Data (SIMD) et représente l'une des approches du calcul parallèle.
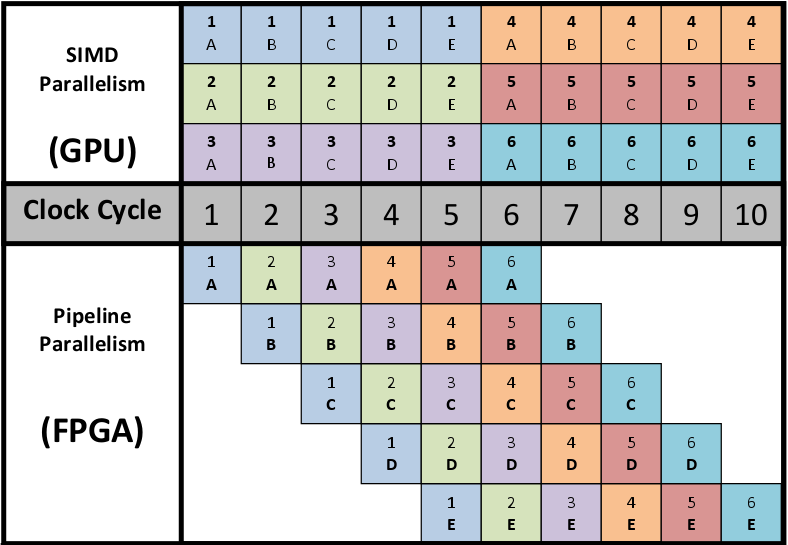
 Figure 47 : Le parallélisme de type pipeline dans les FPGA~: une comparaison avec le SIMD des type des GPU
Figure 47 : Le parallélisme de type pipeline dans les FPGA~: une comparaison avec le SIMD des type des GPU
La spécificité des GPU fait que par cycle d'horloge les unités actives exécutent la même instruction. En conséquence, pour une donnée (couleur dans le diagramme), le calcul sera complet toujours après 5 cycles, correspondants aux 5 instructions à appliquer. Dans cet exemple on étudie le cas pour 6 données présentées au GPU et au FPGA (6 couleurs différentes). Le GPU peut exécuter 3 items en mode SIMD. Dans le FPGA, les items exécutés en parallèle appliquent des instructions différentes sur des données différentes. Avec cette configuration, le traitement des 6 données est complet après 10 cycles d'horloge.
Le FPGA a l'avantage que les différents noyaux (qui exécutent, dans cet exemple, une des 5 instructions) sont compilés dans des circuits hardware séparés. Par cet artifice, sur le premier cycle l'item 1 exécute l'instruction A sur la donnée bleue. Sur le deuxième cycle, l'item 1 continue avec l'instruction B sur la donnée bleue et l'item 2 exécute l'instruction A sur la donnée suivante, verte. Sur le troisième cycle, l'item 3 exécute l'instruction A sur la donnée mauve, pendant que l'item 2 peut exécuter l'instruction B sur la donnée verte (la deuxième du flux des données) et l'item 1 continue sur la bleue (la première du flux de données) avec la troisième instruction, C. Et ainsi de suite.
Même si dans cet exemple on a l'égalité entre le GPU et le FPGA au bout de 10 cycles, on observe qu'à partir du septième cycle d'horloge, les items du FPGA commencent progressivement à ne plus être utilisés. Si on continue le flux des données, le GPU va compléter tout les 5 cycles le calcul sur 3 données d'entrée, pendant que les items du FPGA exécuteront en moyenne toutes les 5 instructions sur le même cycle d'horloge.
Un autre avantage du FPGA par rapport au GPU devient visible quand une instruction (ou un noyau) produit un résultat qui implique une bifurcation de l'exécution suivante, en fonction de la valeur d'entrée. Par exemple, si l'instruction A est exécutée sur le même cycle pour trois données (bleue, verte, mauve) mais la séquence des trois instructions suivante et ramifié en (B$_{1}$ , C$_{1}$ , D$_{1}$ ), (B$_{2}$ , C$_{2}$ , D$_{2}$ ) et (B$_{3}$ , C$_{3}$ , D$_{3}$ ), étant donné que les items synchrones d'un GPU exécutent toujours la même instruction (on ne peut pas avoir B$_{1}$ , B$_{2}$ et B$_{3}$ ), il en résulte que le temps total pourrait s'allonger. Si l'exécution sur la donnée bleue continue avec la séquence (1), celle sur la donnée verte avec la séquence (2) et la mauve avec la séquence (3), le nombre total de cycle d'horloge sera $3 \times 3 = 9$ , au lieu de trois sans bifurcation (figure 47, voir [156]OpenCL on FPGAs for GPU programmers, Acceleware, WP-2014060-1.0). Dans le FPGA chaque cycle est utilisé, car B$_{1}$ , B$_{2}$ et B$_{3}$ seront compilés dans de circuits séparés et le routage des données à la sortie de A est fait selon le branchage spécifiée dans le code (if$\dots$ then).