11.3.4.1 : Vectoriser avec le compilateur
Les compilateurs, comme GCC et G++[72]Gnu C Compiler and Gnu C++ Compiler - GCC/G++, GNU, sont très conservateurs et ne vectoriseront pas les calculs par défaut.
La vectorisation par le compilateur nécessite quelques indices.
Tout d'abord, les tableaux utilisés doivent être alignés, sinon le compilateur ne vectorisera pas les calculs. Pour cela leurs allocations doivent être effectuées avec memalign ou posix_memalign sur MacOS (voirsection 11.3.3.1.2). De plus, les pointeurs utilisés doivent explicitement être déclarés comme alignés avec la fonction builtin_assume_aligned.
Une autre difficulté rencontrée par le compilateur est que les pointeurs C/C++[149]C++ language reference, servant de base aux tableaux dans ces langages, peuvent désigner n'importe quel espace mémoire. Aucune garantie ne permet donc au compilateur de conclure que des tableaux passés en entrée d'une fonction ne se chevauchent pas. Or, cette ambiguïté interdit au compilateur de vectoriser, car en cas de chevauchement la vectorisation change le résultat du calcul.
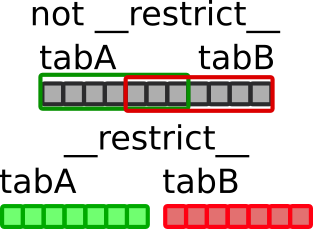
Figure 42 : En haut : si le mot clé __restrict__ n'est pas utilisé, les espaces mémoires peuvent se chevaucher. En bas : si le mot clé __restrict__ est utilisé, les espaces mémoire sont indépendants.
Le mot clé __restrict__ garantit au compilateur que les pointeurs désignent des espaces mémoire différents (voir figure 42). Dans ce cas, l'utilisateur ne doit pas se tromper car le programme produirait alors un résultat faux.
Certaines fonctions de la bibliothèque standard du C, comme memcpy ou memset, sont définies avec le mot clé __restrict__ car le tableau qu'elles utilisent en entrée doit être différent de celui qu'elles utilisent en sortie pour éviter des comportements non souhaités.
Pour finir, la vectorisation doit être explicitement activée avec les options de compilation :
- -ftree-vectorize : active la vectorisation (inclus dans -O3).
- -march=native : utilise tous les jeux d'instructions supportés par la machine hôte.
- -mtune=native : optimise les performances du code sur la machine hôte.
- -mEXTENSION : active un jeu d'instructions vectorielles spécifique.
Où EXTENSION : sse2, sse4, avx, avx2 ou avx512 noteIl existe une vingtaine d'extensions avx512, comme avx512f pour les calculs flottant par exemple..
Avantages : les compilateurs deviennent de plus en plus performants pour vectoriser et optimiser des programmes en général. L'analyse pourra voir son temps d'exécution diminuer rien qu'en changeant de version de compilateur (cependant les accélérations seront faibles à chaque fois). Le code en lui-même est facilement portable entre différents matériels, même si le programme final devra être compilé pour chaque architecture cible afin d'avoir les meilleures performances sur des architectures fortement hétérogènes comme la Grille WLCG[71]WLCG : World-wide LHC Computing Grid, CERN. Cette procédure est une des plus simples pour vectoriser.
Inconvénients : les compilateurs sont très efficaces pour vectoriser des fonctions simples mais atteignent vite leurs limites lorsque les fonctions gagnent en complexité. Par exemple, le calcul de barycentre à deux dimensions est très mal vectorisé et optimisé par le compilateur GCC[72]Gnu C Compiler and Gnu C++ Compiler - GCC/G++, GNU (voir cours [143]How to optimize computation with HPC, Pierre Aubert). Il n'est pas possible d'utiliser de vieux compilateurs comme GCC 4.8 ou antérieurs car leurs capacités de vectorisation sont trop limitées.
Fortran fournit toutes les prédispositions pour la vectorisation~[209]Basics of Vectorization for Fortran Applications, 2018, Lima Pilla, La\'ercio~: dès ses strates les plus anciennes il offre un modèle mémoire suffisamment abstrait par rapport au matériel pour ne pas avoir besoin de préciser restrict comme en C. Par ailleurs, le Fortran "moderne" (post 90) offre des map implicite à travers ses fonctions tableaux, puis (post 95) ses fonctions elemental et ses boucles forall, désormais (08) do concurrent, toutes autant de signaux forts et clairs pour que les compilateurs déchaînent l'auto-vectorisation. Les solutions par directives pour piloter le compilateur dans du code moins contemporains sont également disponibles, notamment !GCC\$ vector, !GCC\$ ivdep et !GCC\$ builtin, ou d'une manière plus indépendante du compilateur dans le cadre d'OpenMP 3+, !\$omp simd~[210]OpenMP Application Program Interface --- Examples, 2016, OpenMP Architecture Review Board. \spaceparagraphe{} Peut-être un petit mot sur le Fortran\cite{refFortran} et ses compilateurs. Je n'en ai pas développé assez pour me permettre de tirer des conclusions dessus, mais si quelqu'un se sent de le faire\dots{} Hadrien: Il n'y a plus besoin de \keyword{restrict} car Fortran suppose que les tableaux d'entrées d'une fonction ne sont pas aliasés par défaut. La sémantique du langage autorise le compilateur à réordonner les opérations flottantes comme il le souhaite tant qu'il n'y a pas de parenthèses. Les {devs} Fortran ont moins peur d'utiliser les fonctionnalités SIMD d'\lib{OpenMP} que les {devs} C++. Pour le reste je ne sais pas, il faudrait demander à Vincent. Vincent\,: un petit fascicule très abordable et concret ce trouve à \url{https://hal.inria.fr/hal-01688488/document}