1.4.1 : Activité système à surveiller
- Utilisation de chaque coeur CPU
- Si un seul coeur est utilisé à plein régime à chaque instant, cela suggère que le programme est limité par la performance CPU séquentielle. Soit il n'est pas parallélisé, soit sa parallélisation est inefficace.
- Sous certains OS, on peut observer que l'utilisation 100% se "déplace" d'un coeur à l'autre à intervalles réguliers de quelques secondes. C'est un comportement normal de l'OS visant à répartir la chauffe thermique entre les coeurs CPU. Il n'a normalement qu'un impact infime sur les performances, mais peut être désactivé si besoin avec des outils comme taskset.
- Répartition de l'utilisation CPU globale en user/kernel/iowait/idle
- Une proportion élevée d'utilisation "kernel" signifie que le programme passe une grande part de son temps à faire des appels systèmes. C'est souvent, mais pas toujours, le signe que ces derniers sont trop nombreux, ex: un appel système par octet lu depuis un fichier. Cela signifie aussi que la performance observée variera beaucoup d'un système à l'autre, voire au fil des mises à jour d'un système.
- Une proportion élevée d'utilisation "iowait" indique que le CPU n'est pas vraiment utilisé pour des tâches de calcul, mais attend des E/S de façon active. Attention, ce compteur n'est pas fiable sur les noyaux Linux moderne : une valeur élevée indique la présence d'un grand volume d'E/S, mais la réciproque est fausse.
- En temps normal, on doit avoir $idle \approx 100\% - (user + kernel)$ . Si ce n'est pas le cas, il faut se pencher sur des postes d'utilisation CPU plus exotiques comme le "nice" et le traitement des interruptions.
- Fréquence et température CPU
- Il est fortement recommandé de surveiller ces deux indicateurs simultanément quand on a accès aux deux, car le second aide à comprendre le premier.
- Une augmentation temporaire de la fréquence CPU au-dessus de la fréquence nominale, qui retombe sous certaines circonstances (ex: activité sur les autres coeurs), est le signe de l'activation du mécanisme "turbo" qu'on a brièvement évoqué précédemment.
- Une diminution de la fréquence CPU sous la fréquence nominale est normale en cas d'inactivité. Si elle se produit alors que les coeurs CPU concernés sont actifs, c'est généralement le signe d'une surchauffe ou d'un problème de synchronisation (ex: threads qui bloquent à tour de rôle sur un mutex). L'examen de la température permet de discriminer entre ces deux scénarios.
- Il est normal pour un CPU de monter à 60°C lors d'une charge prolongée sur tous les coeurs d'un ordinateur fixe. Sur les portables hautes performances, cette "température de confort" peut être plus élevée, parfois 80°C. Des températures supérieures à 90°C sont inacceptables et le signe d'une mauvaise conception ou d'une défaillance (ex: poussière) du système de refroidissement, qui conduiront l'OS à diminuer la fréquence CPU par intermittence, voire à éteindre la machine brutalement. Elles peuvent aussi affecter la durée de vie du matériel sur le long terme...
- Utilisation RAM et swap
- La quantité de RAM allouée par une application n'a pas d'impact direct sur ses performances, seul la portion de cette allocation qui est utilisée à un instant T compte. Mais il y des impacts sur la performance applicative quand la quantité totale de RAM utilisée par le système s'approche des limites physiques.
- Par exemple, sous Linux, toute la mémoire "non utilisée" est employée comme cache des données disque auxquelles l'utilisateur a récemment accédé. Donc plus il y a de RAM utilisée, plus le système doit jeter des éléments de son cache disque. Cela peut nuire à la performance d'applications qui effectuent de nombreux accès disques.
- De plus, plus la quantité de mémoire utilisée est importante, plus l'OS tend à avoir recours au mécanisme de swap évoqué ci-dessus., car dépendant des caractéristiques de l'OS et ses tâches de fond. Ce dernier rend la performance mémoire de l'application non déterministe, car fortement dépendante des caractéristiques de l'OS et de l'activité des tâches de fond.
- A un moment, on arrive au cas extrême où le système doit commencer à mettre en swap des données activement utilisées par l'application, ce qui se produit en général quand toute la RAM physique est utilisée par des données "applicatives". Tout se passe alors comme si la bande passante de la RAM diminuait de plusieurs ordres de grandeur. L'impact sur la performance applicative sera non seulement dramatique (généralement identifié comme un blocage du système, alors que celui-ci continue en fait de fonctionner très lentement), mais aussi dépendant du système de stockage et de l'OS utilisé...
- Débits et opérations/seconde stockage
- On peut approximer grossièrement le temps $T(N)$ qu'il faut à un système de stockage pour répondre à une requête de lecture/écriture d'un volume de données $N$ par une loi affine $T(N) = T_0 + N / B$ où $T_0$ est la latence du système de stockage et $B$ sa bande passante.
- Dans le cas d'un disque dur, $T_0$ est très élevé: de l'ordre de 5ms, soit 20 millions de cycles CPU, ou le temps de lire environ 1 Mo en "régime continu". Un système qui doit répondre à un grand nombre de petites requêtes sera donc essentiellement limité par cette latence du stockage, c'est pourquoi il ne faut pas se contenter de regarder le débit de données mais examiner le nombre d'opérations E/S par seconde en complément.
- Dans le cas des mémoires flash, ces effets sont nettement moins significatifs, mais demeurent présent, et l'indicateur du nombre d'opérations à la seconde reste donc bon à surveiller quand on ne comprend pas pourquoi la bande passante crête du stockage n'est pas atteinte.
- Dans les deux cas, il est important de configurer son moniteur système pour afficher un graphe par support physique de stockage, et pour distinguer les lectures et écritures qui reflètent des comportements applicatifs différents et peuvent avoir des caractéristiques de performances différentes. L'utilisation de graphiques empilés est recommandée car il y a souvent une limite matérielle à la somme des bandes passantes d'entrée et de sortie, et pas seulement à l'une ou l'autre de ces bandes passantes prises individuellement.
- Débits et opérations/seconde réseau
- La motivation est grosso modo la même que pour le stockage, même si le détail des phénomènes en jeu est différent.
- Les mêmes précautions s'appliquent: un graphique d'IOPS (nombre d'entrées/sorties par seconde) et un graphique de débit par interface réseau, avec affichage séparé des entrées et des sorties sous forme de graphiques empilés.
- Activité PCIe et coprocesseurs
- Pour les applications qui utilisent des coprocesseurs, comme les GPUs, il est important de surveiller l'activité de ceux-ci en regard de celle du CPU. On peut en effet observer ainsi quelques anomalies très intéressantes, comme une alternance d'activité CPU et GPU qui illustre un manque d'asynchronisme du côté CPU.
- Dans un monde idéal, on pourrait aussi surveiller l'activité de l'interconnexion entre les deux processeurs, mais malheureusement je ne connais qu'un seul moniteur système qui surveille celle-ci sans se spécialiser du même coup dans la surveillance de l'activité GPU au détriment d'autres analyses...
Voici un exemple de moniteur système graphique généraliste pour Linux, ksysguard, qui a été configuré pour visualiser en un coup d'oeil l'évolution temporelle de toutes les métriques citées ci-dessus, à l'exception de la swap, de la température (le besoin de la surveiller n'étant qu'intermittent, elle est reléguée à un onglet séparé) et de l'activité PCIe/GPU (qui n'est hélas pas supportée par cet outil) :
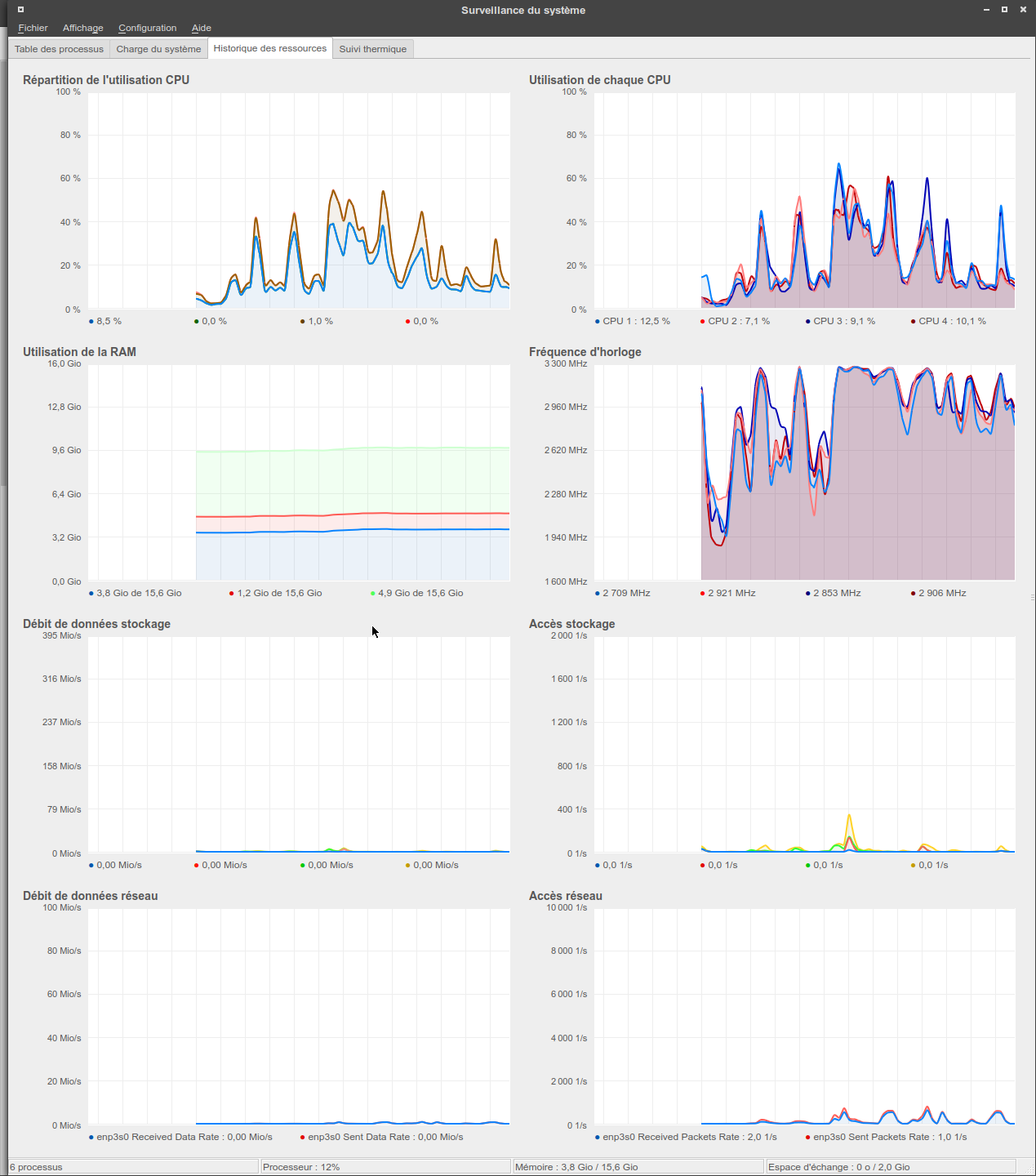
Figure 1 : Surveillance système avec ksysguard