1.4.3 : Logiciels pour Linux (WIP)
Au regard des critères précédents, nous recommandons sous Linux...
- Pour les systèmes graphiques, ksysguard avec une fréquence de rafraîchissement faible sur la page "processus" (elle est coûteuse à rafraîchir) est une option très intéressante. Son principal intérêt par rapport aux autres solutions graphiques est de permettre la création de pages de graphiques complètement personnalisées, tout en perturbant beaucoup moins le système hôte qu'une solution web.
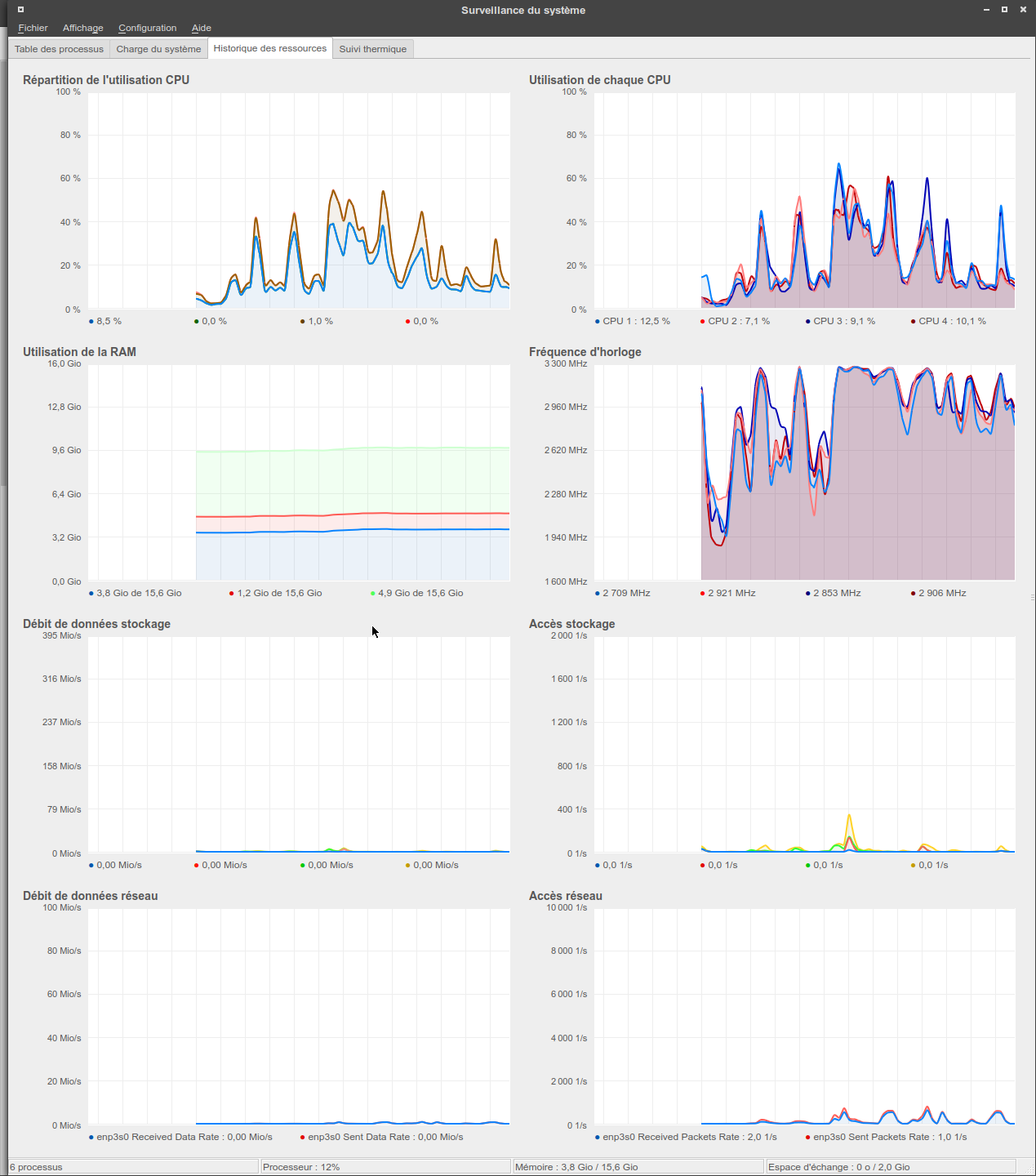
Figure 2 : Surveillance système avec ksysguard
- zenith donne une vue d'ensemble excellente, mais peu configurable.
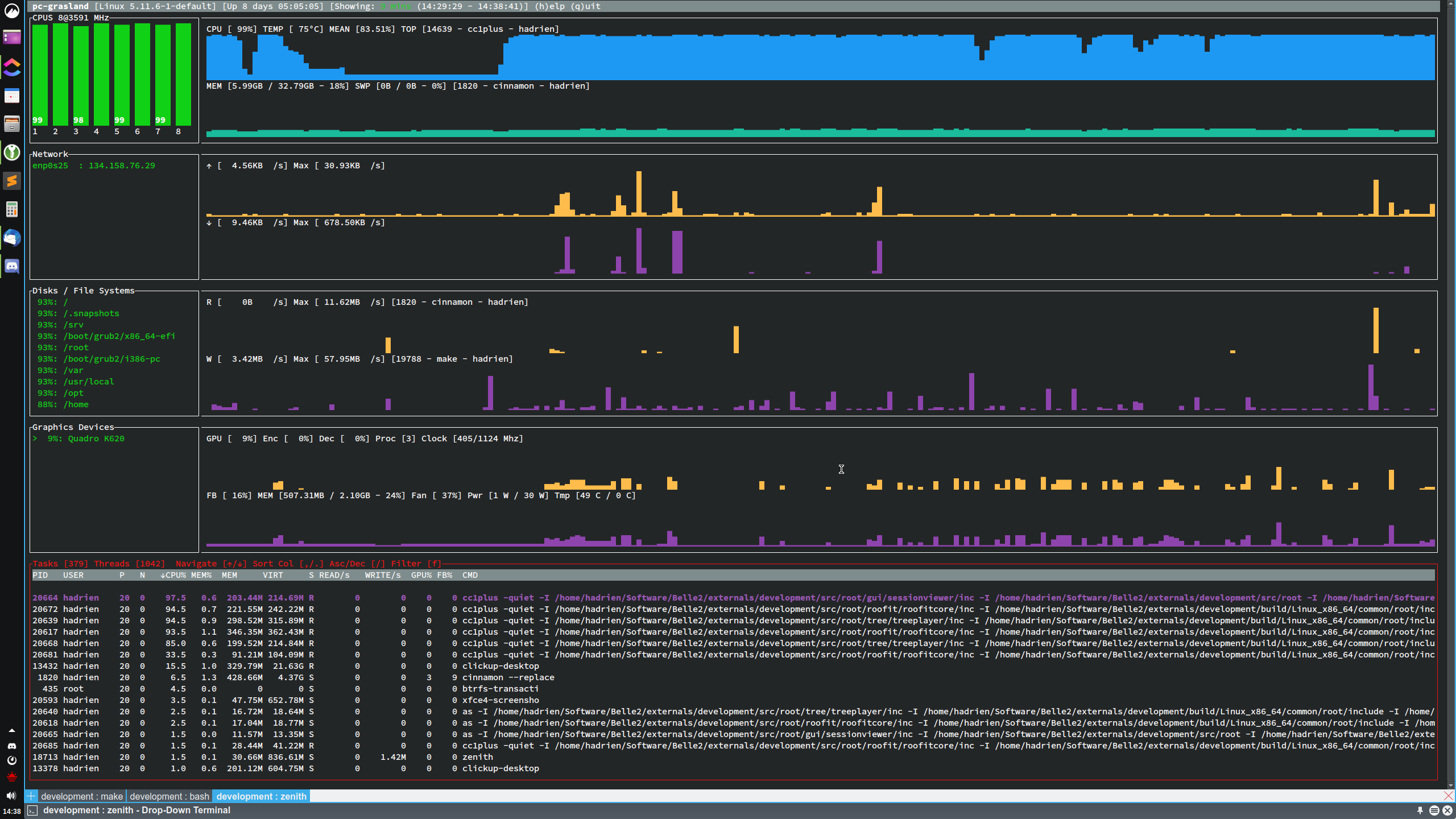
Figure 3 : Surveillance système avec zenith
- Lorsqu'on souhaite davantage de contrôle, dstat est imbattable, hélas son développement a été récemment abandonné donc il y a un risque qu'il disparaisse des dépôts des distributions Linux à l'avenir...
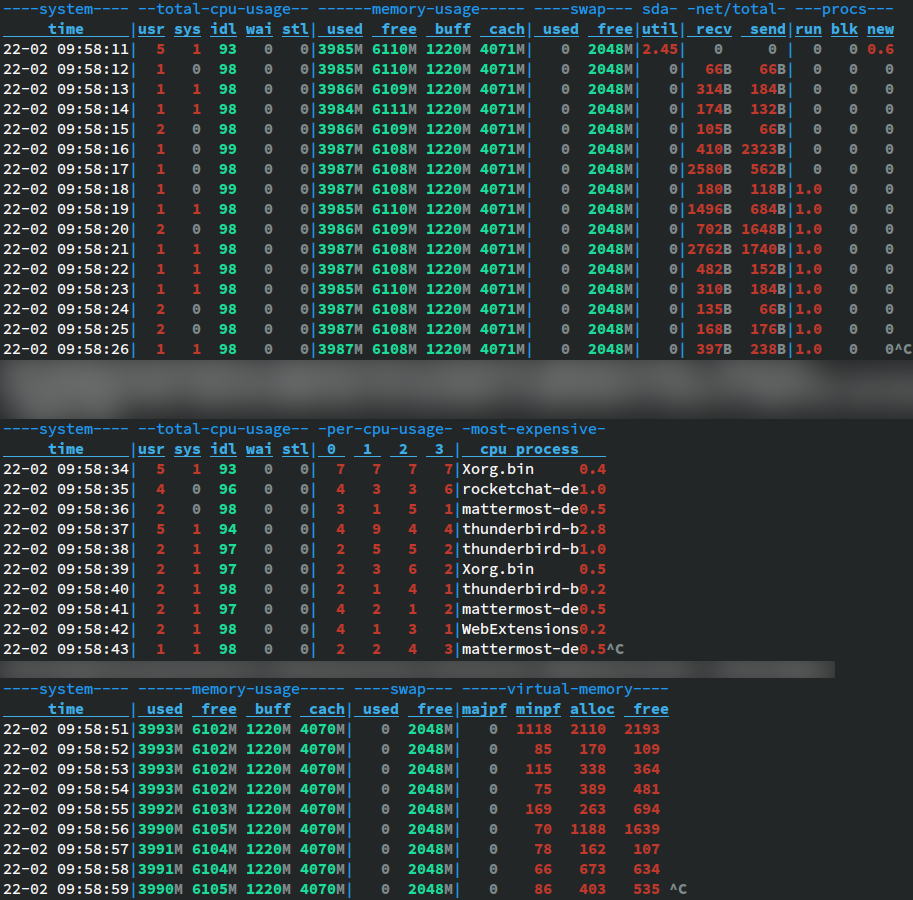
Figure 4 : Surveillance système avec dstat
Si on n'a pas le choix d'utiliser l'un ou l'autre de ces logiciels et doit utiliser un moniteur qui ne montre que l'état "instantané" du système, deux choix intéressants dans ce domaine sont...
- nmon pour une solution dont l'affichage est configurable au gré des besoins.
- glances pour une solution "tout en un" avec d'assez bons réglages par défaut.
Le lecteur averti aura noté que la plupart des solutions proposées n'incluent pas de suivi de l'activité GPU. Malheureusement, il n'existe pas d'API standardisée pour effectuer un tel suivi sous Linux, donc les outils à utiliser sont spécifiques à chaque fabricant de matériel (voire à chaque pilote d'un matériel donné, quand il en existe plusieurs), et ils sont globalement pénibles à installer et utiliser. On peut néanmoins mentionner...
- zenith (ci-dessus) et gmonitor pour les GPUs de marque NVidia.
- radeontop pour les GPUs de marque AMD.
- intel-gpu-tools pour les GPUs de marque Intel.
Du côté Windows, les outils fournis en standard pour le suivi de l'activité système sont très complets et on peut mener des investigations de performances assez poussées sans installer aucun logiciel supplémentaire :
- Le gestionnaire de tâches (Task Manager), accessible rapidement via le raccourci clavier Ctrl + Maj + Echap, présente dans son onglet "Performance" une palette de graphiques remarquablement complète.
- Certains sont configurables par clic droit, par exemple la vue de l'activité CPU peut être configurée pour afficher l'activité de chaque coeur séparément.
- Fait assez rare pour être signalé, la vue GPU est relativement complète et permet de savoir, pour chaque GPU du système, l'activité des unités de calcul et de transfert de données ainsi que le taux de remplissage de la mémoire vidéo dédiée.
- Au niveau des regrets, nous mentionnerons juste la relative simplicité des statistiques CPU (pas de graphique des températures, fréquence aggrégée sur tous les coeurs...), ainsi l'absence de graphiques d'opérations/seconde pour le disque et le réseau. Mais nous pourrons pallier à ces manques en utilisant l'analyseur de performances, décrit ci-après...

Faire quelques captures d'écran. - Le moniteur de ressources (Resource Monitor), accessible notamment par un lien dans l'onglet "Performance" du gestionnaire de tâches, fournit des indicateurs un peu plus détaillés que le gestionnaire de tâches. En particulier, il permet de suivre l'activité de chaque processus plus finement.
Faire une capture d'écran. - Mais pour des besoins plus avancés, le nec plus ultra reste l'analyseur de performances (Performance Monitor), qui permet à la manière de ksysguard sous Linux de se construire des graphiques personnalisés représentant l'évolution temporelle de tous les indicateurs d'activité que l'on souhaite parmi une liste impressionnante. On peut notamment s'en servir pour pallier à l'absence de graphiques précis de température, fréquence CPU et IOPS dans le gestionnaire de tâches.
Faire une capture d'écran.
|
| Je n'utilise pas macOS couramment et n'ai pas accès facile à un Mac, donc je ne peux pas juger de l'offre sous ce système d'exploitation. Mais la plupart des sites que j'ai vu dans ma recherche encensent inconditionnellement le logiciel payant iStat Menus. Un complément d'information des utilisateurs Mac serait bienvenu ici. Et, bien sûr, des captures d'écran. |
Une fois qu'on a établi que le programme est limité au moins une partie du temps par la performance CPU, il est temps d'analyser à quoi ledit CPU passe ce temps. On y trouvera potentiellement des opportunités d'accélérer les choses.
Il existe de nombreux outils pour effectuer cette analyse, chacun avec ses avantages et inconvénients. Nous allons donc faire un petit tour des grandes familles d'approches utilisées par ces outils avant d'aborder des outils particuliers et de ce qu'on peut faire avec.
Le type d'outil que l'on va pouvoir utiliser est en partie conditionné par le type de langage de programmation qu'on utilise, et plus précisément par son mode de compilation/exécution.
En effet, la grande majorité des outils de profilage CPU s'appliquent à des programmes compilés statiquement, c'est à dire où l'on traduit le programme en code machine avant de commencer l'exécution. C'est le processus typique en C/++, Fortran, Rust, Go ou Ada par exemple.
Certains outils peuvent aussi s'appliquer à des programmes compilés à la volée pendant l'exécution. C'est le processus typique en Java, Scala, C#, JavaScript ou Julia; et de façon plus exotique c'est aussi ce que fait l'interpréteur Cling de ROOT avec du code C++. Dans ce cas, pour fonctionner correctement, l'outil de profilage aura besoin que le compilateur à la volée lui transmette certaines informations sur le code généré, ce qui en retour pourra nécessiter de modifier ledit compilateur avec des patches ou des options de compilation/exécution particulières.
En l'absence d'une telle instrumentation du compilateur, ou lorsque le programme est interprété comme on fait typiquement en Python, les outils de profilage CPU classiques ne fonctionneront pas correctement. Les seuls outils disponibles seront alors spécifiques au langage cible (comme cProfile pour Python ou @profile pour Julia), et leur qualité sera malheureusement souvent nettement moindre que celle des outils généralistes puisque le nombre de développeurs potentiellement sujets à y contribuer est bien plus faible.
Enfin, lorsqu'aucun outil ne donne satisfaction, on pourra parfois être amené à effectuer le processus de profilage à la main, par exemple en modifiant le code pour mesurer la valeur d'une horloge avant et après chaque opération de haut niveau et afficher le temps écoulé. Cet exercice étant nettement plus piégeux et chronophage, tout en fournissant moins d'information au final, il est recommandé de ne s'y livrer qu'en dernier recours.
L'un des objectifs les plus importants de l'analyse de l'utilisation du temps CPU est d'estimer quelle proportion dudit temps est passée dans les différentes régions d'un programme. Cela permet de guider le processus ultérieur d'optimisation de performances en indiquant quelles parties du code méritent une attention particulières.
La plupart des outils de profilage CPU utilisent l'une des trois approches suivantes pour mesurer la répartition du temps CPU entre routines:
- Traçage: A chaque fois que le programme passe en un certain point (ex: début/fin d'une fonction), on note le moment où cela s'est produit. Par une analyse ultérieure de ces temps de passage (la plus simple étant $\Delta T = T_fin - T_début$
), on peut voir comment le temps a été passé dans les différentes parties du programme.
- C'est la seule approche de profilage qui soit assez simple pour qu'on puisse, si besoin, la pratiquer "à la main" sans utiliser d'outils. Elle est automatisable par une compilation/interprétation du code instrumentée dans chaque région du code que l'on souhaite étudier. Mais dans un langage compilé statiquement, ce processus peut être très lourd (nécessité de recompiler toutes les bibliothèques utilisées pour un profil détaillé, et d'avoir accès à un support direct du compilateur ou un générateur de code...).
- Il est aussi possible d'enregistrer d'autres informations que le moment où un point de passage a été atteint, par exemple les paramètres d'une fonction. Cela permet d'effectuer des analyses complémentaires intéressantes, par exemple d'étudier la relation entre les paramètres d'une fonction et son temps d'exécution.
- Contrairement aux autres approches de profilage, le traçage mesure le temps réellement passé à exécuter le programme "à la pendule". Il sera donc sensible au temps passé à effectuer des opérations qui ne sont pas gérées par le CPU ou ne font pas partie du code de l'application, comme les entrées-sorties ou les appels système. Les autres techniques ne seront sensibles qu'au temps passé à effectuer certaines opérations, typiquement l'exécution par le CPU du code de l'application, ce qui biaisera leur analyse lorsque le temps passé à effectuer d'autres opérations devient élevé.
- Le principal inconvénient du traçage est qu'il "déforme" le profil de l'application. Plus une fonction est fréquemment appelée et de courte durée, plus son temps d'exécution va être artificiellement augmenté par le temps passé à mesurer et stocker la valeur de l'horloge système. Il est donc assez dangereux d'utiliser le traçage à tous les étages d'une application en même temps, et préférable de ne l'appliquer qu'à un seul niveau d'abstraction à la fois (ex: soit à l'extérieur d'une boucle, soit à l'intérieur, mais pas aux deux endroits à la fois).
- Le coût du traçage peut aussi devenir prohibitif (et donc rendre le profil mesuré non représentatif de l'activité CPU réelle de l'application) si il est appliqué à grain trop fin. C'est donc plutôt une technique appropriée pour l'analyse "à gros grain" d'une application ayant des étapes logiques d'exécution de durée suffisamment longue (au moins quelques µs, et il va de soi que quand on mesure des durées aussi faibles il faut aussi prendre d'autres précautions comme le calcul de statistiques sur plusieurs exécutions).
- Modélisation: Dans cette seconde approche, le profileur instrumente le code à la volée pendant l'exécution pour mesurer le nombre d'exécutions de chaque instruction du programme, et compense le surcoût prohibitif de ce comptage en n'étudiant pas directement le temps écoulé mais une estimation théorique du temps qui aurait été écoulé si ces instructions s'exécutaient sur un CPU idéal sans instrumentation.
- Cette approche permet d'avoir accès à des informations plus fines que le traçage ne peut fournir (ex: profil d'instructions assembleur individuelles, étude des dynamiques de cache et de prédiction de branche...), sans nécessairement avoir accès aux fonctionnalités matérielles de profilage (compteurs de performance).
- Son principal défaut est évidemment la lenteur d'exécution du programme, souvent 30-100x plus long, ce qui nuit à la fluidité du travail de développement. Il faut réfléchir avant d'essayer de compenser ce ralentissement par une diminution de la taille du problème traité par le programme, car cela peut changer ses caractéristiques de performances si certaines opérations ne sont pas linéaires en fonction de ladite taille (ex: phase d'initialisation).
- Un autre problème de cette approche est que comme elle ne ralentit que l'activité CPU du programme, elle tend à négliger l'impact des autres tâches auxquelles le programme peut passer son temps (E/S, appels système, calcul GPU...).
- Même si ce n'est pas une limitation fondamentale de l'approche théorique, la plupart des implémentations actuelles ont de grandes difficultés à bien modéliser l'exécution de tâches parallèles.
- Et enfin, contrairement aux deux autres approches que nous discutons, cette approche ne peut pas être étendue à l'échelle "système" pour suivre du temps CPU passé dans le système d'exploitation, puisque ledit système deviendrait alors trop lent pour être utilisable.
- Pour conclure, mentionnons que sur des programme simples respectant diverses restrictions, il est parfois possible de modéliser les performances du programme sans exécuter réellement le programme, juste en analysant le binaire "à froid". C'est par exemple ce que font l'outil "CQA" (Code Quality Analyzer) de la suite MAQAO et l'outil llvm-mca fourni avec le compilateur LLVM.
- Echantillonnage: L'exécution du programme est périodiquement interrompue par l'outil de profilage, qui examine quelle instruction CPU est actuellement en train d'être exécutée (et éventuellement la pile d'appel sous jacente). Une analyse statistique permet ensuite de déterminer quelles sont les régions du programme où une grande partie du temps CPU est passé.
- Dans l'ensemble, cette approche est plus générale et entâchée de biais moins grossiers que les deux précédentes, c'est pourquoi elle est la plus utilisée dans les outils actuels.
- La fréquence d'échantillonage est une variable d'ajustement très puissante: plus elle est faible, moins le profilage perturbe l'exécution du programme, et plus elle est grande, plus le profil d'exécution obtenu à la fin est précis.
- En phase d'exploration, il est important d'acquérir des profils du programme à différentes fréquences d'échantillonage et de les comparer pour gérer certains biais : échantillon qui tombe toujours au même point d'une tâche périodique du programme sans "voir" le reste, fréquence d'échantillonage trop élevée qui biaise le profil...
- Le profilage par échantillonage bénéficie particulièrement de benchmarks dont l'exécution est longue, qui leur permettent d'accumuler autant de statistiques que nécessaire sans avoir recours à une fréquence d'échantillonage élevée. C'est particulièrement vrai quand on cherche une information à grain fin (ex: instructions "chaudes" dans l'assembleur du programme), dont l'estimation statistique a besoin d'un très grand nombre d'échantillons pour converger.
Au delà de ces techniques de mesure fondamentales, les profileurs se distinguent aussi les uns des autres au niveau du type d'activité qu'ils peuvent mesurer et de la sophistication de l'analyse statistique qu'ils effectuent en fin de mesure:
- Graphes d'appels:
- Les profileurs les plus simples ne font qu'estimer une répartition du temps d'exécution du programme entre fonctions de ce dernier. Cette information est généralement insuffisante pour analyser des applications complexes, car elle ne permet pas de distinguer différentes causes d'appel à une fonction générale (ex: allocateur mémoire, bibliothèque d'algèbre), ni à l'inverse de réaliser que certaines fonctions sont souvent appelées ensemble dans le cadre d'une activité de plus haut niveau.
- Les graphes d'appel répondent à ce problème en fournissant un profil hiérarchique où l'on connaît le temps passé non seulement dans une fonction, mais dans les fonctions "enfant" appelées par cette dernière.
- Leur calcul est complexe, car il nécessite l'analyse des piles d'appel du programme, qui sont profondément affectées par les optimisations de compilateur. On peut distinguer trois méthodes:
- L'utilisation du frame pointer comme lien vers la fonction appelante. Cette technique est simple et à faible coût, donc utilisée par de nombreux outils, mais avec des compilateurs modernes elle est malheureusement perturbée par certaines optimisations qu'il faut désactiver non seulement pour l'application mais pour l'ensemble des bibliothèques utilisées par celle-ci (flag -fno-omit-frame-pointer pour GCC). Cela implique généralement la recompilation de toutes les bibliothèques utilisées.
- L'utilisation du compteur de performance Last Branch Record du CPU. Cette technique est encore moins chère que la précédente, mais elle nécessite un accès privilégié au matériel, un système d'exploitation à jour par rapport au modèle de CPU utilisé, un CPU compatible (>=Haswell chez Intel), et elle ne peut remonter qu'à une certaine hauteur dans la pile d'appel (typiquement une dizaine de fonctions) ce qui rend le profil difficile à interpréter dans des applications complexes.
- L'enregistrement de copies du haut de la pile du programme à chaque échantillon et l'analyse ultérieure de ces copies partielles de la pile avec l'aide des symboles de déboguage (DWARF). Cette technique est coûteuse en termes de surcoûts de profilage et d'espace disque consommé, elle nécessitera donc généralement une fréquence d'échantillonage faible. De plus, elle n'est pas infaillible (on peut avoir besoin d'une info au-delà de la région de pile enregistrée, les infos de déboguage peuvent être incorrectes...). Mais malgré tous ses défauts, elle reste la plus facile à utiliser, puisqu'elle n'a besoin que des symboles de déboguage de l'application et de ses dépendances, qui sont généralement fournis par les distributions Linux sous forme de paquets spéciaux (paquets -debuginfo sous SUSE). De plus, elle permet certaines analyses que les autres techniques ne permettent pas, comme une estimation de l'impact des fonctions inlinées sur les performances de leur fonction hôte.
Une capture d'écran de perf report, hotspot ou VTune aiderait à comprendre ce concept. - Profilage système:
- Les profileurs les plus simples ne s'intéressent qu'à l'activité CPU d'un processus unique (voir un fil d'exécution unique, dans le cas d'outils particulièrement peu recommandables), ce qui les conduit à négliger l'activité CPU qu'une application déclenche au sein du noyau du système d'exploitation (appels système) et d'autres processus (composants systèmes hors noyau: udev, serveur X...), et à ne pas donner d'indication de l'activité système de fond pouvant perturber les mesures de performances.
- Pour éviter ce biais, il faut surveiller l'activité de l'ensemble du système, pas seulement de l'application qu'on cherche à optimiser. Mais il va sans dire qu'un tel suivi système d'ensemble a des implications en termes de sécurité informatique (espionnage), et qu'il nécessite donc des privilèges spéciaux et une intégration d'une partie de la mécanique de mesure du profileur au sein du noyau du système d'exploitation. Ce qui ne sera pas sans causer parfois quelques frictions avec les équipes administratives de noeuds de calcul partagés...
Une capture d'écran de perf top aiderait à comprendre ce concept. - Profil assembleur:
- Certains outils basés sur une approche de modélisation, ou sur une approche d'échantillonage avec suffisamment de statistiques, permettent de repérer des instructions CPU particulièrement "chaudes" dans une fonction. Cette fonctionnalité peut être très utile dans une optique de micro-optimisation.
- Moyennant la disponibilité des symboles de déboguage DWARF, certains outils peuvent tenter, avec plus ou moins de succès, de relier l'assembleur profilé aux lignes de code source du programme dont elles sont issues. Il faut bien être conscient qu'en présence d'optimisations de compilateur, cet exercice est fondamentalement piégeux.
Une capture d'écran de perf annotate, VTune ou KCacheGrind aiderait à comprendre ce concept.
Les CPU modernes sont capables de fournir des informations extrêmement précises sur leur activité: nombre de cycles d'horloge écoulés, d'instructions exécutées, de branches (bien prédites ou non), d'accès mémoires (avec ou sans défaut de cache à tel ou tel niveau de la hiérarchie), et bien d'autres choses.
Un profileur étant intégré au niveau du noyau du système d'exploitation peut potentiellement interroger ces compteurs à toutes sortes de fins:
- Travailler en cycles d'horloge plutôt qu'en secondes, ce qui peut permettre des résultats plus reproductibles sur des systèmes dont la fréquence d'horloge est variable (même si faut prendre garde au fait que les performances mémoire ne varieront pas de façon synchrone).
- Repérer les régions du code où un grand nombre de défauts de cache surviennent, ce qui suggère qu'un travail sur l'organisation des données en mémoire est nécessaire.
- Repérer les régions du code où le prédicteur de branche se trompe souvent, ce qui suggère qu'il faut mieux ségréger les données d'entrée par catégories afin de faciliter la vie à cette partie du CPU.
- Repérer les régions du code où les opérations mathématiques sont ralenties par toutes sortes de problèmes : nombres spéciaux IEEE-754 (dénormaux, NaNs), basculements fréquents SSE/AVX, utilisation insuffisante de la vectorisation...
- Repérer des problèmes liés à la synchronisation entre fils d'exécution (opérations atomiques, false sharing...).
Sur des programmes suffisamment simples, de type microbenchmarks, il peut suffire de faire un suivi des comptes "bruts" de divers événements CPU sur l'ensemble de l'exécution un programme, et des métriques composites qui en découlent (instructions par cycle, bande passante cache/mémoire consommée...), pour obtenir des informations très utiles au processus d'optimisation.
|
| Une capture d'écran de perf stat aiderait à comprendre ce concept. |
Sur des applications plus complexes, il est plus intéressant d'analyser quelles régions du code sont associés à un taux élevé de certains événements matériels (comme les défauts de cache).
- On l'a vu, les pauvres utilisateurs de langages dont l'implémentation n'est pas compatible avec les profileurs généralistes (Python) ou n'a pas été compilée avec ce support activé (paquets Julia de certaines distributions Linux) sont forcés de s'en remettre à un profileur intégré. Puisqu'il serait très fastidieux d'écrire une section profilage pour chacun de ces langages de programmation, qui ne ferait souvent guère plus que de dire qu'il n'y a qu'un seul outil utilisable (et donc pas de choix), mettre un lien vers sa documentation, et lamenter ses limites par rapport aux outils généralistes, nous supposerons dans le reste de cette section que l'utilisation des profileurs généralistes est possible.
- Sous Linux, perf est un logiciel incontournable pour l'étude de l'activité CPU.
- Dans son utilisation la plus simple, c'est un profileur par échantillonage.
- Il est capable de mesurer à peu près tout: activité d'une application unique ou d'un système entier, suivi du temps d'exécution ou des compteurs de performances, support de plusieurs algorithmes de calcul de graphe d'appel, granularité d'affichage du profil configurable du processus à l'assembleur... En fait, son utilité dépasse même le simple cadre CPU, puisqu'il est aussi capable de faire du traçage d'activité noyau, à fin d'étude de problèmes d'ordonnancement ou d'entrées sorties.
- Il a fait le choix d'une interface en ligne de commande, ce qui a un coût en termes d'ergonomie, mais permet en contrepartie l'utilisation sur des noeuds de calcul ne disposant pas d'une pile graphique.
- Son principal inconvénient est que pour qu'il fonctionne bien en toute circonstance, il faut disposer d'une version du noyau Linux ayant un bon support de son modèle CPU, ce qui est grosso modo assuré si elle est sortie ultérieurement. Cette condition, qui peut sembler en apparence simple, se révèle difficile à assurer en pratique sur les systèmes Red Hat présents sur de trop nombreux noeuds de calcul.
- Sans noyau à jour, les premières fonctionnalités touchées sont celles ayant trait aux compteurs de performance avancés (défauts de cache, mauvaise prédiction de branchement...) et aux graphes d'appel LBR. Les fonctionnalités de profilage en temps devrait continuer à fonctionner normalement même quand le système d'exploitation est un peu antidaté, mais aucune garantie ne peut être offerte avec certitude.
- A part ça, perf souffre aussi d'une documentation un peu austère à base de pages de man. Il est recommandé d'utiliser en complément ce tutoriel de ma fabrication et la page de Brendan Gregg sur le sujet.
- Il existe une interface graphique à perf, hotspot, mais à l'heure où ces lignes sont écrites (2020) elle est d'une stabilité approximative et ne donne accès qu'à une petite partie des fonctionnalités de perf. Elle ne peut donc pas remplacer l'outil en ligne de commande pour l'instant.
Mettre une capture d'écran de perf ici (ça peut être une des précédentes).
- Quand on ne peut pas utiliser perf, un bon second choix est callgrind de la suite Valgrind, accompagné de l'interface graphique KCacheGrind.
- callgrind est un profileur basé sur une approche par modélisation (lire les avertissements ci dessus). Il a depuis quelques temps intégré les fonctionnalités de simulation de hiérarchie de cache de son cousin cachegrind, ce qui fait qu'on n'a plus très souvent besoin d'avoir recours à ce dernier.
- callgrind ne peut suivre qu'une application et ses processus fils. Il mesure des profils à plat, des piles d'appel, rapporte les résultats avec une granularité de "ligne de source code reconstruite" ou d'assembleur, et simule la prédiction de branche et le cache CPU avec un réalisme modéré. En tant que tel, il offre déjà une bonne palette d'outils pour commencer.
- La simulation des fils d'exécution de Valgrind, dont callgrind dépend, est très primitive et relève d'un simple entrelacement des instructions en un programme séquentiel. Il est fortement déconseillé d'utiliser callgrind pour analyser la performance d'un programme multi-thread.
- KCacheGrind fournit une interface graphique pour l'exploration des profils callgrind qui est honnêtement un cran au-dessus de l'interface textuelle de perf et des tentatives d'interface graphique en développement pour ce dernier (hotspot), même si il faut quand même un petit temps d'apprentissage pour la prendre en main.
Mettre une capture d'écran de KCacheGrind ici (ça peut être une des précédentes).
- Les outils Intel, tels que le profileur VTune Amplifier, peuvent aussi être intéressants à utiliser car ils bénéficient d'une grande popularité (donc de bons tutoriels sur internet), d'une interface graphique très poussée, d'un bon support des systèmes d'exploitation Windows et macOS, et d'outils sympathiques d'analyse automatique du profil de l'application. Toutefois, certains sont assez chers, des retours que nous en avons eu ils tendent à être gourmands en ressources et d'une stabilité imparfaite, et il est ennuyeux de dépendre pour ses analyses de performances d'un outil lié à un fabriquant de CPU spécifique. Comme des alternatives qui n'ont pas ces problèmes existent, nous ne parlerons pas davantage de ces outils.
Mettre une capture d'écran de VTune ici (ça peut être une des précédentes). - Le profileur gprof, intégré au compilateur GCC car il utilise une approche hybride entre instrumentation (pour les piles d'appel) et échantillonage (pour le suivi de l'exécution), était autrefois une référence du fait de sa simplicité d'utilisation. Toutefois, il a de nombreuses limitations très gênantes que n'ont pas les outils ci-dessus, ce qui fait que nous aurions tendance à décourager son emploi aujourd'hui:
- gprof est incapable de rendre compte précisément de l'utilisation de bibliothèques partagées par le programme, ce qui le rend inutilisable dès qu'une application devient un tant soit peu complexe.
- gprof n'est pas capable de rendre compte correctement de l'utilisation CPU de par plusieurs fils d'exécutions (threads).
- L'utilisation de gprof ralentit l'exécution de code CPU (et donc biaise le profil de performance mesuré) à un degré bien plus élevé que des outils plus modernes comme perf.
- Pour suivre les processus fils d'une application, il faut que tous les exécutables sous-jacents aient eux aussi été recompilé avec l'instrumentation gprof.
- Sous macOS, il est courant d'utiliser le profileur Instruments intégré à la suite XCode, et sous Windows il est courant d'utiliser l'utilitaire Windows Performance Analyzer (WPA), qui est inclus dans le Windows Assessment and Deployment Kit (Windows ADK) et s'appuie sur l'infrastructure Event Tracing For Windows (ETW). Ces deux outils sont gratuits, mais faute d'expérience de ces systèmes dans l'équipe, nous ne pouvons pas en dire plus sur leurs caractéristiques et leur mode d'emploi pour le moment.
|
| Dans la version simplifiée, il faudra probablement s'en tenir à un résumé en un paragraphe par outil : ce qu'il fait bien, ergonomie, domaine d'application (petit grain, gros grain...)... |
|
| Ici se tiendra le glorieux tutoriel Reprises sur la bonne manière
d'analyser ses accès disques et réseaux! Mais pour l'heure, je n'ai pas assez potassé le sujet pour faire ne serait-ce qu'un bon article introductif dessus... Je soupçonne qu'éplucher les parties de http://www.brendangregg.com/qui causent de cette question serait un bon premier pas. |
Le modèle de programmation des GPUs est quelque peu plus complexe à apréhender que celui des CPUs, car...
- Leur contrôle est beaucoup moins direct, il s'effectue par le biais d'interfaces plus abstraites (OpenGL, Direct3D, Metal, Vulkan, CUDA, OpenCL, SyCL, ...).
- Les divergences conceptuelles entre ces differentes interfaces GPU sont plus grandes qu'entre les modèles de programmation CPU.
- Les interfaces GPU, versionnées, sont en évolution relativement rapide en comparaison avec les interfaces CPU.
- Un matériel donné sur un système d'exploitation donné ne supportera pas toutes les interfaces, ni toutes les versions d'une interface donnée.
- Entre le CPU et le GPU, il y a une interconnexion (généralement le bus PCI-express) dont les caractéristiques de latence et de bande passante sont bien plus mauvaises que celles des bus mémoire respectifs du CPU et du GPU.
- Avoir un programme dont les performances sont limitées par les piètres capacités de cette interconnexion est un rite de passage pour le programmeur GPU débutant.
- Bien gérer cette interconnexion demande un certain doigté même pour le programmeur GPU confirmé.
- Le GPU est une architecture un peu plus "rigide" que sur le CPU sur plusieurs aspects (quantité de ressources mémoire privées et partagées, mécanismes de soumission et d'éxécution de travail, granularité des transferts mémoire et plus généralement sensibilité aux "motifs" d'accès mémoire, synchronisation...)
- Cela en fait parfois oublier les points où le modèle de programmation GPU est, à l'inverse, plus accomodant que celui des CPUs: support natif d'un nombre de tâches bien plus grands que le nombre d'unités d'exécution disponibles, instructions conditionnelles et lectures/écritures mémoire dispersées dans le code vectoriel...
Pour gérer ces complexités spécifiques, l'utilisation d'outils d'analyse de performances spécialisés est extrêmement précieuse.
On distingue deux grandes familles d'outils pour l'analyse des performances GPU: ceux qui travaillent au niveau des APIs (généralement par interposition d'une "fausse" implémentation de l'API qui appelle l'API véritable en faisant du traçage) et ceux qui travaillent au niveau des pilotes de matériel.
Les premiers sont relativement nombreux, peuvent être open source, et sont souvent accomodants en termes de support d'OS et d'APIs. Les seconds sont la chasse gardée des fabricants de matériel et entièrement tributaires de la politique de ceux-ci (par exemple un outil de profilage NVidia n'offrira quasiment aucun support de l'API OpenCL, et un outil Intel sera souvent commercial et onéreux).
En contrepartie, les outils qui travaillent au niveau des pilotes de matériel sont capables de fournir des informations plus précises, par exemple sur l'activité du bus PCIe ou l'utilisation des unités d'exécution du matériel. Ces informations sont précieuses pour le processus d'optimisation, elles diminuent le nombre de choses que l'on doit deviner à partir des seules informations exposées par les APIs.
- "Temps morts" côté CPU ou GPU:
- Les outils de profilage GPU fournissent souvent au moins une vue "binaire" de l'activité CPU et GPU au fil du temps. Si ces deux composants ne sont pas actifs en permanence, il faut se demander pourquoi, puisqu'on laisse du temps de calcul sur la table.
- Si le CPU est inactif par intermittence, c'est généralement le signe qu'il est en train d'attendre que le GPU finisse une tâche. Si ces phases sont longues, il y a intérêt à soumettre du travail au GPU de façon asynchrone, et effectuer un autre travail sur le CPU en attendant que le GPU ait fini ses tâches.
- Si le GPU est inactif par intermittence, c'est généralement le signe que le CPU ne lui fournit pas du travail assez rapidement, ou pas assez de travail par commande d'API. Il faut alors prioriser davantage la soumission de travail au GPU, l'optimiser si elle est trop lente, s'assurer que le GPU ait toujours trop de travail à un instant T donné (il y a une file d'attente), et soumettre davantage de travail par appel d'API.
Une capture d'écran de NSight ou équivalent aiderait à comprendre. - Programme limité par les transferts de données:
- Les outils de profilage opérant au niveau des pilotes de matériel sont en mesure d'indiquer si le GPU passe son temps à transférer des données, exécuter du code, ou les deux à la fois. Cette information est précieuse.
- Si le GPU passe le gros de son temps à transférer des données, il faut corriger ça. Quelques techniques classiques sont de générer les données aléatoires sur le GPU au lieu de les générer/envoyer côté CPU, de réduire les résultats sur le GPU plutôt que de les envoyer au CPU et faire la réduction là-bas, de compresser les données côté CPU et les décompresser côté GPU, de garder les données sur le GPU aussi longtemps qu'elles y sont utiles au lieu de les renvoyer à répétition, et de garder sur le GPU des tâches qui seraient un peu plus efficaces sur le CPU pour limiter les échanges CPU/GPU.
- Si le GPU alterne entre transferts de données et exécution de code, alors il faut revoir l'architecture du code pour soumettre des tâches de transfert de données et d'exécution de code au GPU en parallèle avec une synchronisation appropriée, histoire d'avoir en même temps l'exécution du job N, l'envoi des données d'entrées du job N+1, et la réception des données de sortie du job N-1.
Une capture d'écran de NSight ou équivalent aiderait à comprendre. - Programme limité par l'exécution de code:
- Comme avec le code CPU, une fois qu'on a réussi à atteindre le point où le GPU passe le gros de son temps à exécuter du code, il faut encore s'assurer que ladite exécution soit efficace.
- Les détails seront en partie spécifiques à chaque matériel, les GPUs étant un peu moins standardisés que les CPUs, et les outils de précision étant, on l'a vu, spécifiques à chaque matériel et chacun avec sa logique propre... Mais dans l'ensemble, il faut s'assurer...
- Que toutes les unités d'exécution travaillent
- Qu'un usage efficace est fait des différentes ressources mémoire (registres, mémoire partagée d'une unité d'exécution, mémoire globale...)
- Que la vectorisation est efficace (pas trop de divergence)
- Qu'il n'est pas fait un usage excessif de la synchronisation
- Que l'exécution des kernels est assez longue pour compenser leurs coûts de lancement
- Comme avec le code CPU, on s'intéressera évidemment en premier lieu aux kernels dont les temps d'exécution sont les plus longs...
Une capture d'écran de NSight Compute ou équivalent aiderait à comprendre.
|
| Il faut que j'aille faire un peu de biblio pour voir c'est quoi les
outils les plus à la mode actuellement. Par rapport aux noms que je connais, cette liste me semble être un bon point de départ: https://www.khronos.org/opengl/wiki/Debugging_Tools. Mais il faudra filtrer les outils de profiling et ceux de pur debug. De plus, elle est un peu faible sur les outils spécifiques aux fabriquants. P. ex. on ne mentionne qu'un outil parmi la pléthore que fournissent Intel et NVidia, et pour ce dernier ils n'évoquent même pas l'excellent nvvp. Il faudra faire un tour sur les sites de fabricants pour compléter Il manque aussi des outils spécifiques OS, ex: Intruments sous macOS sait faire du profiling GPU je crois (mais jamais testé), et il me semble que sous Windows WPA peut parler un peu de GPU aussi si on lui demande gentiment. Et il y a aussi GPUView à creuser. Une autre liste d'outils de profilage GPU est disponible sur https://gist.github.com/silvesthu/505cf0cbf284bb4b971f6834b8fec93d. |
|
Quelques sujets qui attendront sans doute la v2 du site, mais dont je pense qu'il serait très intéressant de parler à un moment...
|
|
| il manque un truc |